CySparse for library maintainers¶
Warning
TO REWRITE COMPLETELY
The main difficulty to maintain the CySparse library is to understand and master the automatic code generation from templated source code. We use the template engine Jinja2 and some hard coded conventions. We explain and justify these conventions in the following sections.
The sparse matrix formats are detailed in the section Sparse Matrix Formats.
Versions¶
The version is stored in the file __init__.py of the cysparse subdirectory:
__version__ = "0.1.0"
The version can be anything inside the quotes but this line has to be on its own and start with __version__ = " (notice the one space before and after the equal sign). See the function find_version() in the file setup.cpy for more details.
Workflow¶
Here is my (Nikolaj) (non-automated and using git flow) workflow:
git flow release start v0.7.3;- Do whatever adjustments needed (mainly change version
__version__and updateREADME.mdwith- Version 0.7.3 released on Apr 18, 2016),commitandpushthose; git flow release finish v0.7.3;git push;git checkout master;git push --follow-tags;git checkout develop.
Optionally, you can also update the documentation with the new tag version. Do this only if you skimmed through the doc and know for sure that it is up to date with the new release.
Meta-programming aka code generation¶
CySparse allows the use of different types at run time and most typed classes comes in different typed flavours. This feature comes with a price. Because we wanted to write the library completely in Cython, we decided to go for the explicit template route, i.e. we write templated source code and and use explicit names in the source code. This automatic generation process ask for some rigour and takes some time to master. If you follow the next conventions stricly, you should be fine. If you don’t follow them then probably the code won’t even compile or if it does you might generate difficult to find bugs. Trust me on this one.
Warning
Follow the conventions stricly to write templated source code.
Justifications¶
Following conventions is not always easy, especially if you don’t understand them. In this sub-section we try to convince you or at least we try to explain and justify some choices I (Nikolaj) made (and try to follow).
These conventions were made with the following purpose in mind:
- respect the DRY (Don’t Repear Yourself) principle;
- if the conventions are not followed, the code shouldn’t compile;
- prefer static over dynamic dispatch;
- use typed variables whenever possible;
- keep the code simple whenever it doesn’t sacrifice to efficiency even if the solutions are not Pythonesque;
We develop these key ideas in the following sub-sections.
Respect the DRY principle¶
Don’t write the same code twice. This means of course than whenever you can factorize some common code, you should do so but in our case, because we lack the notion of templates (like C++ templates), we have to repeat ourselves and rewrite the classes with different types. This is the main reason to use a template engine and templated code. That said, some code has been duplicated because I (Nikolaj) could not find how to make it work in Cython. One example is the proxy classes: they all share common code. I wasn’t able to make them inherit from a base class [1].
If the conventions are not respected, the code shouldn’t compile¶
To enforce the use of the conventions, we try to enforce them by the compiler (whether the C, the Cython or Python compiler). Often, you’ll find that templated code have guards to ensure that types are recognized and otherwise to generate garbish that won’t compile.
The name convention is written explicitely: if you don’t respect it, you won’t be able to use the generate_code.py script. This is on purpose.
Prefer static over dynamic dispatch¶
Even if Python is a dynamic language, efficient Cython code needs typing. This typing can be done dynamically with long and tedious if/then combinations or we can let the compiler
do the dispatch in our place at compile time whenever possible. This is the main reason why there are as many LLSparseMatrixView classes as there are LLSparseMatrix classes. Strictly speaking, we don’t need
more LLSparseMatrixView classes than the number of index types but then you need to dynamically dispatch some operations like the creation of a corresponding ``
Use typed variables whenever possible¶
Cython really shines when it can deduce some static typing, especially in numeric loops. Therefor try to type variables if you know their type in advance [2].
Our hope is to keep a nice balance between the difficulty of coding and the easiness to maintain the code. When generating automatically code, these two don’t necessarily go hand in hand.
If you find some code that doesn’t follow these conventions, report it or even better change it!
Types¶
Basic types¶
For different reasons [3] (???)
We use the following basic types:
| CySparse | C99 types |
|---|---|
INT32_t |
int |
UINT32_t |
unsigned int |
INT64_t |
long |
UINT64_t |
unsigned long |
FLOAT32_t |
float |
FLOAT64_t |
double |
FLOAT128_t |
long double |
COMPLEX64_t |
float complex |
COMPLEX128_t |
double complex |
COMPLEX256_t |
long double complex |
Two categories of types¶
We allow the use of different types at two levels:
- for the indices (
INT32_tandINT64_t) [4]; - for the matrix elements (all the basic types).
Add (or remove) a new type¶
Conventions¶
File names and directories¶
To keep the generation of code source files as simple as possible, we follow some conventions. This list of conventions is strict: if you depart from these conventions, the code will not compile.
Don’t use fused types: this feature is too experimental.
Template files have the following extensions:
Cython CySparse template File type .pxd.cpdDefinition files. .pyx.cpxImplementation files. .pxi.cpiText files to insert verbatim. For python files:
Python CySparse template File type .py.cpyPython module files. Any template directory must only contain the template files and the generated files. This is because all files with the right extension are considered as templates and all the other files are considered as generated (and can be thus automatically erased). This clear distinction allows also to have a strict separation between automatically generated files and the rest of the code.
Index types are replaced whenever the variable
@index@is encountered, Element types are replaced whenever the variable@type@is encountered.Generated file names:
- for a file
my_file.cpxwhere we only replace an index typeINT32_t:my_file_INT32_t.pyx; - for a file
my_file.cpxwhere we replace an index typeINT32_tand an elment typeFLOAT64_t:my_file_INT32_t_FLOAT_t.pyx.
- for a file
Generated class/method/function names:
Jinja2 conventions¶
Automatic generation scripts¶
All generated files can be generated by invoking a single script:
python generate_code.py
Conventions¶
Names¶
Types¶
All classes are typed and almost all algorithms used specialized typed variables. Many algorithm are specialized for one type of variable. This allows to have optimized algorithms but at the detriment of being able to mix types. For instance, most of the methods of sparse matrices only works for one dtype and one itype.
How to expose enums to Python¶
Even if recently Cyhton exposes automagically enums to Python (see https://groups.google.com/forum/#!topic/cython-users/gn1p6znjoyE), don’t count on it. The convention is
to expose equivalent strings to the user. This string is then translated internally by the corresponding enum. For instance, the enum value UMFPACK_A UmfPack system parameter can be
given as the string ‘UMFPACK_A’ by the user (as a parameter to a solve() method for instance). Internally, this string is translated:
def solve(..., umfpack_sys_string='UMFPACK_A', ...):
cdef:
int umfpack_sys = UMFPACK_SYS_DICT[umfpack_sys_string]
...
In Cython code, you are free to directly use the enum itself.
Class hierarchy¶
The class hierarchy may seems strange at first and indeed is strange. In my wildest dreams (I = Nikolaj) I would like to have a base class MatrixLike from which all other classes inherit.
Something like this [5]:
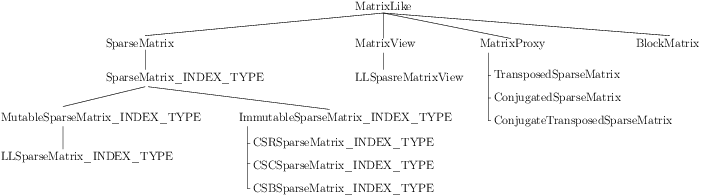
The ideal (?) class hierarchy
While this makes perfect sense at first, it is not very practical with the current situation of Cython and its inability to really use templates. For instance, the MatrixLike class should have
nrow and ncol as attributes but this cannot be done for the moment as both attributes are better typed [6]. Thus, nrow and ncol must be defined in SparseMatrix_INDEX_TYPE, and then
again in LLSparseMatrixView_INDEX_TYPE and then again... We could define a base MatrixLike_INDEX_TYPE class and so on.But the point is that MatrixLike would be quite empty. Basically, I tried to keep it simple and
without too many inheritance. The resulting class hierarchy is far from optimal (and is strange [7]) but is - in my view - a good compromise between code complexity (maintenance), code
duplication and ease of use but also Cython’s limitations (See [1]).
The current situation is:

Current class hierarchy
which involves some code duplication and the use of global functions.
Footnotes
| [1] | (1, 2) See https://github.com/PythonOptimizers/cysparse/issues/113 for more about this issue. |
| [2] | Use your intelligence and knowledge of Cython. Know when it makes a difference to type a variable. |
| [3] | we use C99 for its superiority compared to ANSI C (C89 or C90 which is the same). Among others:
|
| [4] | We don’t want to enter into the debate unsigned vs signed integers. Accept this as a fact. Beside, we use internally negative indices. |
| [5] | Note that some classes don’t exist yet. |
| [6] | Of course, one could argue that we could use non typed attributes in MatrixLike. |
| [7] | Especially with the SparseMatrix class split in two (SparseMatrix and SparseMatrix_INDEX_TYPE)), LLSparseMatrixView_INDEX_TYPE on its own and
non typed proxies. |